
التكرار هو روح اللغات، فكل كلمة تقرؤها ابتكرها في البداية عدد من البشر، وتم استخدامها بعد ذلك من قبل أناس آخرين، ما تسبب مع مرور الوقت بظهور وتعزيز كل من السياق، المعنى والجوهر الذي تقوم عليه اللغة. عندما يدرب البشر الآلات على فهم اللغة، فإنهم يعلمونها ضمناً أن تقلد التحيز عند البشر.
تقول آيلين كاليكسان من مركز سياسات تقانة المعلومات في جامعة برينستون: “إن الاكتشافات العلمية الرئيسية التي يمكننا إظهارها وإثباتها، هو أنه يمكن للغة أن تعكس أشكال التحيز”، وتضيف: “إذا ما تم تدريب الذكاء الاصطناعي على لغة البشر، ستتمكن عندها بالضرورة من استيعاب أشكال التحيز هذه، فهي تمثل حقائق وإحصاءات ثقافية عن العالم”.
تم الأسبوع الماضي نشر عمل كاليكسان، الذي شارك في تأليفه كل من جوانا برايسون، وآرفيند نارايانان في مجلة ساينس (Science). وقد أظهرت نتائجهم بشكل أساسي أن قيام شخص ما بتدريب آلة على فهم لغة البشر سيقتضي التقاط هذه الآلة لأشكال التحيز التي تتضمنها أيضاً.
إن إحدى أفضل الطرق لقياس التحيز عند البشر هي اختبار الارتباطات الضمنية، وفيها يتم الطلب من الأشخاص الربط بين كلمة مثل “حشرة” مع كلمة مثل “جذابة” أو “كريهة”، ثم يتم قياس التأخر، أو الزمن الذي يستغرقه الشخص لإيجاد هذا الربط. عادة ما يكون البشر سريعين في تصنيف الحشرات على أنها كريهة وأقل سرعة في تصنيفها على أنها جذابة، ما يعتبر معياراً جيداً لقياس الترابطات.
يعتبر قياس الحيرة عند الحواسيب أمراً غير عملي، لذا وجد الباحثون طريقة مختلفة لمعرفة أي الكلمات التي تميل الحواسيب أكثر لربطها بكلمات أخرى. بطريقة مشابهة لتخمين الطلاب لمعنى كلمة غير مألوفة بناءً على الكلمات التي تظهر بجوارها فقط؛ قام الباحثون بتدريب ذكاء اصطناعي على ربط الكلمات التي تظهر بجوار بعضها البعض على الإنترنت، وعدم الربط بين الكلمات الأخرى التي لا تحقق هذا الأمر.
تخيل كل كلمة كمتجهة أو شعاع ضمن فضاء ثلاثي الأبعاد. والآن، من أجل كل كلمة ضمن جملة معينة، تكون الكلمات التي يشيع استخدامها ضمن الجملة ذاتها أقرب إلى هذه الكلمة، بينما تكون الكلمات التي يندر استخدامها ضمن الجملة ذاتها أكثر تباعداً. وبالتالي، كلما زاد التقارب بين كلمتين معينتين، كلما زاد احتمال أن تربط الآلة بينهما. إن قال الناس كلمة “مبرمج” بالقرب من “هو” ومن “حاسوب”، في الوقت الذي يقولون فيه “ممرضة” بالقرب من “هي” و “زي”، فسيظهر عندها ذلك التحيز الضمني في اللغة.
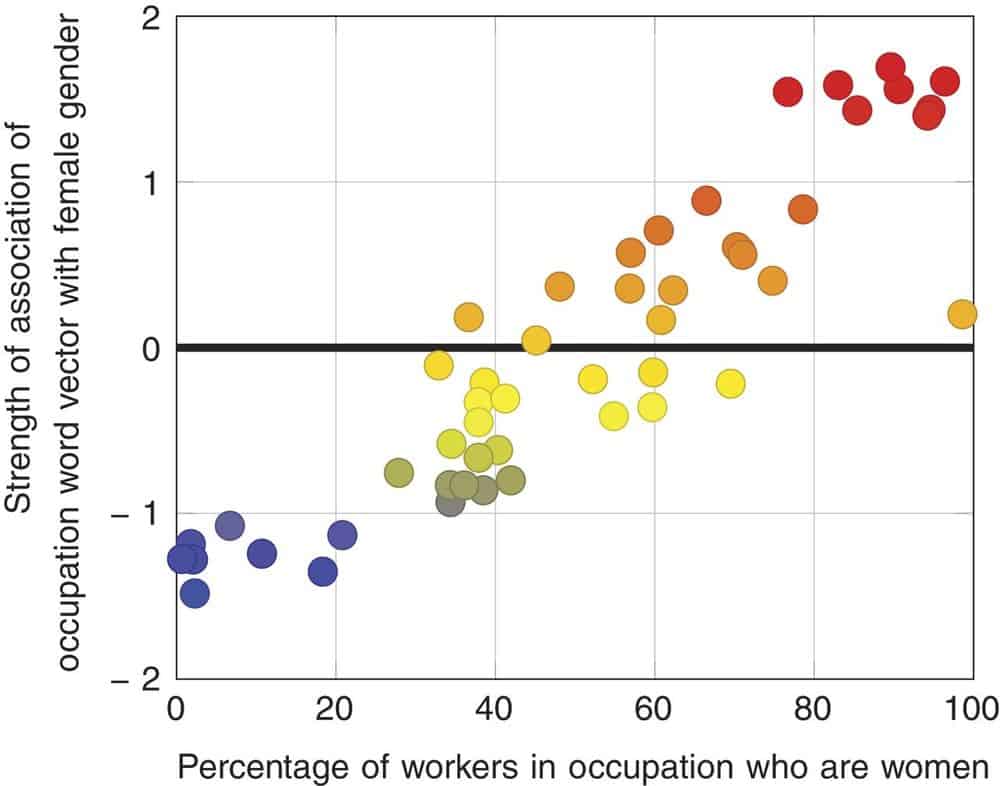
أسماء المهن المرتبطة بالنساء لديها نسبة أعلى من العاملات الإناث.
على محور السينات (محور X الأفقي)، تتوضع البيانات الصادرة عن مكتب إحصائيات العمل في الولايات المتحدة والتي تظهر الأعداد النسبية للنساء العاملات في مهنة ما. بينما يمثل محور العينات (محور Y العمودي) قوة ترابط الكلمات مع المهنة في مجموعة كبيرة من بيانات استخدام الكلمات على شبكة الإنترنت عموماً.
إن تزويد الحواسيب بهذا النوع من المعطيات اللغوية في سبيل تعليمها ليس بالمفهوم الجديد. إذ تقوم أدوات مثل “المتجهات العامة لتمثيل الكلمات” من جامعة ستانفورد GloVe – المتوفرة قبل نشر هذه الورقة البحثية – برسم المتجهات (الأشعة) بين الكلمات المترابطة بناءً على استخدامها. حيث تشمل مجموعات الكلمات الخاصة بهذه الأداة 27 ملياراً من الكلمات التي تم استخراجها من 2 مليار تغريدة، و6 مليارات كلمة تم استخراجها من ويكيبيديا عام 2014، و840 مليار كلمة مستخرجة عشوائياً من الإنترنت.
تقول برايسون: “يمكنك القول: “كم مرة ترِدُ كلمة ’’سلسلة (رسن)‘‘ مع كلمة ’’قطة‘‘؟”. والقول: “كم مرة ترد كلمة ’’سلسلة (رسن)‘‘ مع كلمة ’’كلب‘‘؟”. والقول: “كم مرة ترد كلمة ’’سلسلة (رسن)‘‘ مع كلمة ’’عدالة‘‘؟”، ويمكن لذلك أن يكون جزءاً من الخصائص المميزة للكلمة”. وتضيف: “ثم يمكن مقارنة هذه المتجهات مع دالات جيب التمام (cosine: النسبة بين مسقط المتجهة على محور السينات وطول المتجهة). ما مدى التقارب بين قطة وكلب؟ وما مدى التقارب بين قطة وعدالة؟”.
مثلما يظهر اختبار التقارب الضمني أي المفاهيم يفكر فيها البشر لا شعورياً على أنها جيدة أو سيئة، كذلك فإن حساب المسافات المتوسطة بين المجموعات المختلفة من الكلمات يظهر للباحثين التحيزات التي بدأت الحواسيب بإظهارها في فهمها للّغة. من الملفت للنظر كيف أن الآلات المُدرَّبة على فهم اللغة قد أدركت تحيزات البشر حول الزهور (على أنها جذابة) والحشرات (على أنها كريهة)، وتقول برايسون إن الدراسة كانت لتكون على قدر من الأهمية لو كان هذا كل ما توصلت إليه، إلّا أنها ذهبت إلى أبعد من ذلك.
تقول كاليسكان: “يوجد اختبار ثان، وهو قياس الفارق الكمي بين النتائج التي توصلنا إليها والإحصاءات التي يتم نشرها بشكل علني”. وتضيف: “عدت إلى إحصائيات مكتب العمل للعام 2015، وكل عام كانوا يقومون بنشر أسماء المهن مع نسب النساء، ونسب أخرى مثل نسبة الأمريكيين السود على سبيل المثال من العاملين في تلك المهنة. بعد تفحص مجموعة تضم 50 من أسماء المهن وحساب ارتباط كل منها مع كون صاحب المهنة ذكراً أم أنثى، حصلت على ترابط بنسبة 90% مع بيانات مكتب العمل، الأمر الذي كان مفاجئاً للغاية، إذ لم أكن أتوقع أن أتمكن من إيجاد هكذا ترابط انطلاقاً من بيانات مشوشة بهذا الشكل”.
وبالتالي يمكن للحواسيب أن تدرك العنصرية والتمييز بناءً على الجنس عبر ربط الكلمات المتعلقة بالأعمال مع جنس معين، أو مجموعة عرقية معينة. أحد الأمثلة التي تم التركيز عليها في الورقة البحثية هي كلمة “مبرمج”، وهي كلمة لا تحمل دلالة عن جنس الموصوف بها في اللغة الإنجليزية، إلا أنه ونظراً للطريقة التي تستخدم بها فإن لها مدلولات عن كونها مهنة ذكورية.
تقول برايسون: “لم نأخذ بعين الاعتبار أنه عندما تقول كلمة مبرمج هل تقصد ذكراً أم أنثى”. وتضيف: “إلا أنه تبين لنا أن هذه المعلومة موجودة ضمن السياق الذي ترد فيه الكلمة عادة”.
ستتمكن الآلات المدربة على مجموعات البيانات الخاصة باللغة كما يتم استخدامها (مثل أداة GloVe) من إدراك هذا الترابط، لأنها تمثل السياق الحالي، ولكن ذلك يعني أنه ينبغي للباحثين مستقبلاً توخي الحذر في كيفية استخدام هذه البيانات، بما أن التحيزات البشرية ترد بشكل متضمن فيها. عندما دربت كاليسكان الأداة باستخدام مجموعة الكلمات المستخرجة من موسوعة ويكيبيديا على الإنترنت، والتي تلتزم معياراً تحريرياً يتسم بلغة حيادية، وجدت أنها تحتوي على التحيز ذاته الذي وجدته في مجموعات أكبر من الكلمات المستخرجة من الإنترنت.
ارتباط الكلمات مطابق للتوزيع على أساس الجنس للأسماء الصالحة للجنسين
بالنظر إلى مجموعة الأسماء حيادية الجنس (مثل “أليكس” و “تايلور”)، وجد الباحثون أن كلما ازداد ارتباط الاسم مع الأنوثة على الإنترنت، كلما كانت نسبة النساء ضمن الأشخاص الذين يحملون هذا الاسم أعلى.
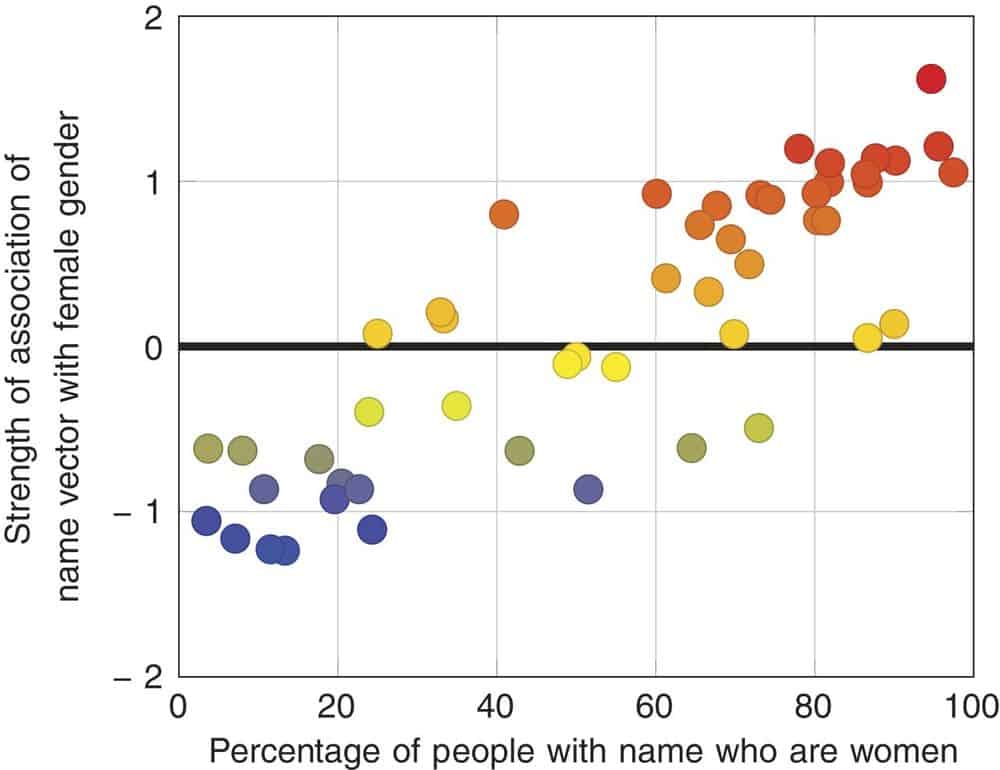
بالنظر إلى مجموعة الأسماء حيادية الجنس (مثل “أليكس” و “تايلور”)، وجد الباحثون أن كلما ازداد ارتباط الاسم مع الأنوثة على الإنترنت، كلما كانت نسبة النساء ضمن الأشخاص الذين يحملون هذا الاسم أعلى.
تقول كاليسكان: “إذا ما أردنا أن ندرك وجود التحيز، وإن أردنا ألّا نكون متحيزين، فنحن بحاجة إلى تحديد التحيز كمياً”. وتضيف: “كيف يدخل التحيز في اللغة، هل يبدأ الناس ببناء ارتباطات متحيزة انطلاقاً من الطريقة التي يتعرفون بها على اللغة؟ معرفة ذلك ستساعدنا أيضاً في الحصول على إجابات للوصول ربما إلى مستقبل أقل تحيزاً”. قد يكون أحد الحلول هو الالتفات إلى لغات أخرى، حيث ركزت الدراسة على كلمات اللغة الإنجليزية المنتشرة على الإنترنت، لذا فالتحيزات التي وجدتها في استخدام الكلمات هي التحيزات التي تجد عادةً لدى الناطقين بالانجليزية والذين يتوفر لديم نفاذ إلى الانترنت. هي تحيزات البشر الناطقين باللغة الإنجليزية والقادرين على الوصول إلى الإنترنت.
تقول كاليسكان: “نحن ندرس أنماطاً مختلفة من اللغات، ونحاول بناءً على قواعد اللغة إدراك ما إذا كانت تؤثر على القوالب النمطية المتعلقة بنوع الجنس أو التمييز على أساس الجنس، بسبب قواعد اللغة وحدها”. وتضيف: “بعضها لا يحمل دلالات عن نوع الجنس، في حين يركز بعضها أكثر قليلاً على نوع الجنس. توجد ضمائر في اللغة الإنجليزية تحمل دلالات عن نوع الجنس، إلا أن هذه الدلالة تزداد قوةً في لغات مثل الألمانية التي تحمل الأسماء فيها دلالة عن نوع الجنس، ويمكن للأمور أن تذهب أبعد من ذلك. فاللغات السلافية لديها صفات تحمل دلالات عن نوع الجنس بل وحتى أفعالاً، ولدينا تساؤلات عن مدى تأثير ذلك على التحيز بناء على نوع الجنس في المجتمع”.
إن فهم كيفية وصول التحيز إلى لغة ما، هو أيضاً وسيلة لفهم المعاني المتضمنة الأخرى التي يضيفها الناس للكلمات إضافة إلى معانيها الصريحة الواضحة.
تقول جوانا برايسون، أحد مؤلفي الدراسة: “بطريقة ما يساعدني ذلك على التفكير في موضوع الوعي”. وتضيف: “ما فائدة الوعي؟ أنت تريد أن تكون لديك ذاكرة العالم بأسره، تريد أن تعلم ماهي الأمور التي تحدث عادةً. هذه هي ذاكرتك الدلالية”.
تتابع برايستون: “تريد أن تكون قادراً على خلق واقع جديد”، ثم تضيف: “قرر البشر أننا رتبنا أمورنا بشكل جيد بما فيه الكفاية اليوم، بحيث يمكن للنساء أن تعمل وتمضي في تطوير مسيرتها المهنية، ويبدو هذا الأمر معقولاً تماماً للقيام به. والآن بإمكاننا التفاوض حول اتفاق جديد، مثال: “لن نقول إن ’’المبرمج هو‘‘ (أي مذكر مفرد)، بل سنقول “المبرمجون هم” (صيغة الجمع المذكر)، حتى لو كنا نتكلم عن مفرد، لأننا لا نريد أن نوحي للناس بأنه لا يمكنهم أن يصبحوا مبرمجين”.
ومالم يقم الناس بتوضيح هذه التحيزات أثناء برمجة الآلات للتعرف على لغات البشر، فلن يقوموا عندها بتطوير آلات غير منحازة، بل آلات تقلد أشكال التحيز عند البشر.
تقول كاليسكان أخيراً: “يعتقد العديد من الناس أن الآلات حيادية”، وتضيف: “الآلات ليست حيادية. إذا ما كانت لديك خوارزمية تسلسلية تقوم باتخاذ القرارات بشكل متسلسل، مثل التعلم الآلي، فأنت تعلم أنها مدربة على مجموعة من البيانات ذات المنشأ البشري، وبالنتيجة لابد لها أن تعرض وتعكس هذه البيانات، وبما أن البيانات جرى تجميعها سابقاً وتتضمن أشكالاً من التحيز، فلا بد للنماذج المدربة من أن تتضمن هذه التحيزات أيضاً، وذلك في حال كانت خوارزمية التدريب جيدة. وإن كانت دقيقةً كفاية، فستكون قادرة على إدراك كافة الارتباطات. فنظام التعلم الآلي يتعلم ما يراه”.