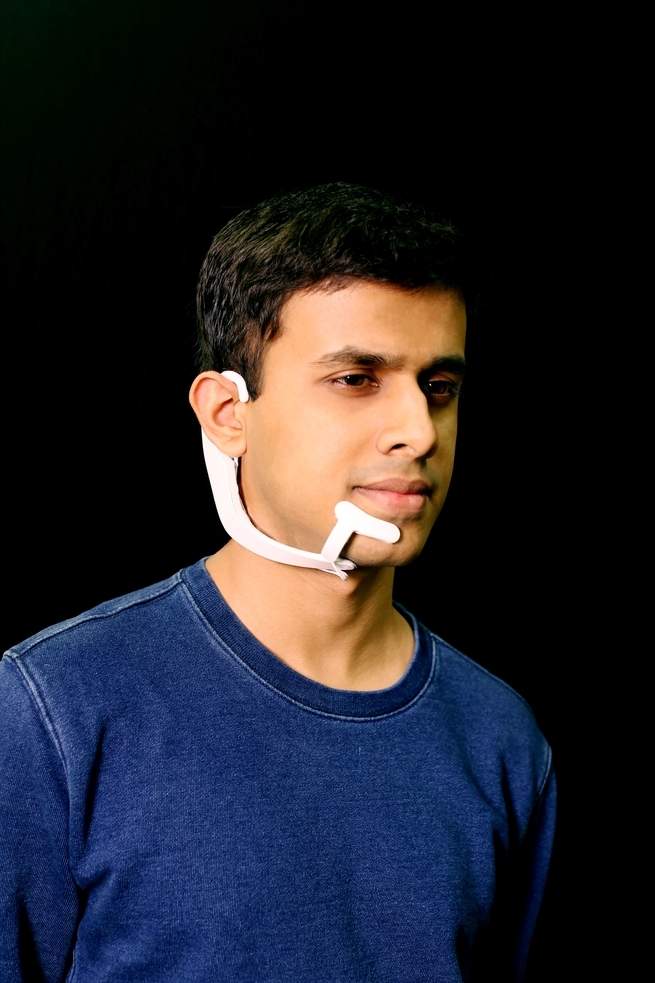
قام طلاب من معهد ماساتشوستس للتكنولوجيا (إم آي تي) بصنع نموذج أولي لأداة، أطلق عليها اسم ألتر إيجو، قادرة على التعرف على الكلمات التي تقولها بصمت عندما تحرك فمك متحدثاً مع نفسك، وحتى تنفيذ بعض الأفعال بناء على ما تعتقد الأداة أنك تقوله.
قام أرناف كابور بتصميم هذه الأداة، وهو طالب ماجستير في مختبر إم آي تي للميديا –وهو قسم في إم آي تي يركز على التفاعل ما بين البشر والتكنولوجيا- ومؤلف البحث، ويؤكد على أن الأداة لا تقرأ الأفكار أو الكلمات العشوائية المنفردة التي تمر في الذهن بالصدفة. ويقول: "تعمل الأداة عندما تكون صامتاً تماماً، ولكنك تتحدث مع نفسك. ليس الكلام العادي أو التفكير المنفرد، بل ما يقع بينهما تماماً، وهو فعل إرادي ولكنه خصوصي أيضاً. لقد تمكنا من التقاطه".
يبدو الجهاز بتصميمه الحالي أشبه بسماعة رأس من النوع الذي يستخدمه موظفو التسويق عبر الهاتف. ولكن بدلاً من الميكروفون، تلتصق الأداة بالوجه والعنق، حيث تقوم مجموعة من الأقطاب الكهربائية بالتقاط الإشارات الكهربائية الصغيرة التي تولدها الحركات الدقيقة للعضلات عندما تتكلم مع نفسك بصمت. تتصل الأداة مع حاسوب بالبلوتوث، ومن ثم مع مخدّم يقول بتفسير الإشارات لتحديد الكلمات التي "يتلفظ" بها المستخدم.
ما زالت الأداة في المرحلة التجريبية، على الرغم من أنها تمثل تغييراً مذهلاً. حيث أننا نتفاعل في أغلب الأحيان مع أجهزتنا عن طريق اللمس، مثل النقر على شاشة هاتف ذكي، أو الضغط على أيقونة تطبيق، أو النقر المزدوج على جانب سماعات آيبود من آبل لإيقاف أو تشغيل الموسيقى. أو عن طريق الكلام مع أجهزتنا أو السماعات الذكية المزودة بمساعدين رقميين مثل سيري وأليكسا وجوجل أسيستانت. تتطلب هذه الأدوات التكلم بصوت واضح. أي أن هذه التقنية تشبه وجود نسخة بسيطة من سيري تصغي إلى همساتك الصامتة.
أما الهدف من هذا، فهو "الجمع ما بين البشر والحواسيب" وفقاً لكابور. وكلما كان التواصل بيننا وبين الحواسيب أقوى، كلما كانت استفادتنا منها أكبر – مثل الحصول على إجابة سريعة حول مسألة رياضية أو ترجمة – بدون ترك العمل والنقر أو الضغط أو الكتابة.
يمكن للمستخدم أيضاً أن يعتمد على هذه التقنية لتغيير القنوات على المشغلات الرقمية للميديا من Roku – بدلاً من أجهزة التحكم الصغيرة التي تضيع بسهولة – بصمت تام. ويبدو أن ألتر إيجو واعدة أيضاً بالنسبة لذوي الاحتياجات الخاصة أو الشلل. غير أن كابور يقول إنهم لم يتمكنوا من دراسة هذا التطبيق بعد.
ما زالت التقنية في مراحلها المبكرة، ولا يمكن لكل تطبيق منها أن يتعلم أكثر من 20 كلمة مختلفة. حيث أن النظام لا يستطيع إلا أن يفهم الكلمات التي تعلمها، وليس كل كلمة يقولها الشخص. ويقول كابور أنه يمكن تدريب الأداة بسهولة عن طريق التحدث مع نفسك بشكل متعمد بدون صوت. وعند التدريب، يُطلب من المستخدم أن يقرأ مقطعاً ما بصوت واضح، وبعد هذا "يُطلب من المستخدم أن يقرأ نفس المقطع بدون صوت. إن هذا مريح أكثر من أن يسمع الأخرون صوتك" وفقاً لكابور.
استخدم كابور لبناء النظام أداة معروفة في مجال الذكاء الاصطناعي تسمى الشبكة العصبونية، وهي قادرة على التعلم من المعلومات المدخلة إليها. وتم تدريب الشبكة العصبونية على التعرف على العلاقة ما بين الإشارات الكهربائية والكلمات التي يقولها الشخص لنفسه.
قد يكون من السهل أن نتخيل تطبيقات عسكرية لهذه الأداة، حيث صرح البروفسور ثاد ستارنر من كلية الحوسبة في معهد جورجيا للتكنولوجيا على موقع إم آي تي أنه يمكن استخدام هذه التقنية من قبل عناصر القوات الخاصة، غير أن كابور يقول إن هذا ليس الهدف من هذه التقنية: "إن الهدف الأساسي هو ردم الهوة ما بين الحواسيب والبشر". والسيناريو المثالي لاستخدامها هو عندما يتمكن البشر من تعزيز قدراتهم بالذكاء الاصطناعي بشكل سلس وفي الزمن الحقيقي.
أما الخطوة المقبلة فهي العمل على شكل الأداة بحيث تصبح "أقل بروزاً". يتمحور كل التصميم حول التكامل السلس، وبالتالي فإن الإصدارات اللاحقة من هذه الأداة يجب ألا تبدو كسماعة عامل تسويق مثبتة بالشريط اللاصق.